[1]:
%load_ext autoreload
%autoreload 2
%matplotlib inline
Cross Validation
TimeGapSplit
We allow for a timeseries split that contains a gap.
You won’t always need it, but sometimes you consider these two situations;
If you have multiple samples per timestamp: you want to make sure that a timestamp doesn’t appear at the same time in training and validation folds.
If your target is looking \(x\) days ahead in the future. In this case you cannot construct the target of the last x days of your available data. It means that when you put your model in production, the first day that you are going to score is always x days after your last training sample, therefore you should select the best model according to that setup. In other words, if you keep that gap in the validation, your metric might be overestimated because those first x days might be easier to predict since they are closer to the training set. If you want to be strict in terms of robustness you might want to replicate in the CV exactly this real-world behaviour, and thus you want to introduce a gap of x days between your training and validation folds.
TimeGapSplit provides 4 parameters to really reproduce your production implementation in your cross-validation schema. We will demonstrate this in a code example below.
Examples
Let’s make some random data to start with, and next define a plotting function.
[2]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import timedelta
from sklego.model_selection import TimeGapSplit
[3]:
df = (pd.DataFrame(np.random.randint(0, 30, size=(30, 4)), columns=list('ABCy'))
.assign(date=pd.date_range(start='1/1/2018', end='1/30/2018')[::-1]))
print(df.shape)
# For performance testing
if False:
df = pd.concat([df]*50000, axis=0)
df = df.reset_index(drop=True)
df.index = df.index + 22
print(df.shape)
(30, 5)
[4]:
df.head()
[4]:
| A | B | C | y | date | |
|---|---|---|---|---|---|
| 0 | 5 | 23 | 13 | 9 | 2018-01-30 |
| 1 | 4 | 13 | 24 | 4 | 2018-01-29 |
| 2 | 18 | 20 | 27 | 5 | 2018-01-28 |
| 3 | 2 | 4 | 8 | 19 | 2018-01-27 |
| 4 | 13 | 26 | 20 | 29 | 2018-01-26 |
[5]:
def plot_cv(cv, X):
"""
Plot all the folds on time axis
:param pandas.DataFrame X:
"""
X_index_df = cv._join_date_and_x(X)
plt.figure(figsize=(16, 4))
for i, split in enumerate(cv.split(X)):
x_idx, y_idx = split
x_dates = X_index_df.iloc[x_idx]['__date__'].unique()
y_dates = X_index_df.iloc[y_idx]['__date__'].unique()
plt.plot(x_dates, i*np.ones(x_dates.shape), c="steelblue")
plt.plot(y_dates, i*np.ones(y_dates.shape), c="orange")
plt.legend(('training', 'validation'), loc='upper left')
plt.ylabel('Fold id')
plt.axvline(x=X_index_df['__date__'].min(), color='gray', label='x')
plt.axvline(x=X_index_df['__date__'].max(), color='gray', label='d')
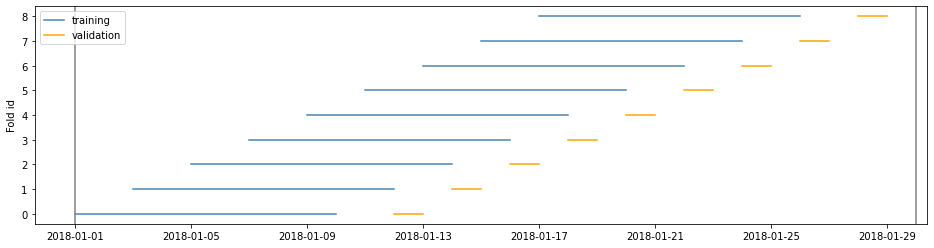
Example 1
[6]:
cv = TimeGapSplit(date_serie=df['date'],
train_duration=timedelta(days=10),
valid_duration=timedelta(days=2),
gap_duration=timedelta(days=1))
[7]:
plot_cv(cv, df)
Example 2
[8]:
cv = TimeGapSplit(date_serie=df['date'],
train_duration=timedelta(days=10),
valid_duration=timedelta(days=5),
gap_duration=timedelta(days=1))
[9]:
plot_cv(cv, df)
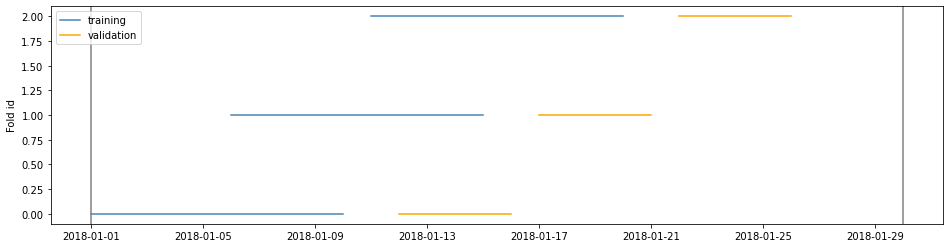
Example 3
window=‘expanding’ is the closest to the sklearn implementation
[10]:
cv = TimeGapSplit(date_serie=df['date'],
train_duration=timedelta(days=10),
valid_duration=timedelta(days=2),
gap_duration=timedelta(days=1),
window='expanding')
[11]:
plot_cv(cv, df)
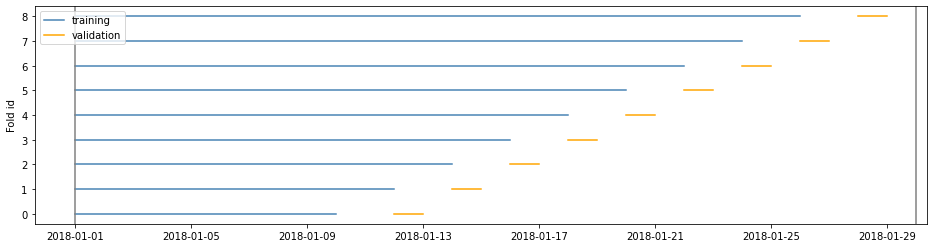
Example 4
If train_duration is not passed the training duration is the maximum without overlapping validation folds
[12]:
cv = TimeGapSplit(date_serie=df['date'],
train_duration=None,
valid_duration=timedelta(days=3),
gap_duration=timedelta(days=2),
n_splits=3)
[13]:
plot_cv(cv, df)

Example 5
If train and valid duration would lead to unwanted amounts of splits n_splits can set a maximal amount of splits
[14]:
cv = TimeGapSplit(date_serie=df['date'],
train_duration=timedelta(days=10),
valid_duration=timedelta(days=2),
gap_duration=timedelta(days=1),
n_splits=4)
[15]:
plot_cv(cv, df)

[16]:
cv.summary(df)
[16]:
| Start date | End date | Period | Unique days | nbr samples | |
|---|---|---|---|---|---|
| (0, train) | 2018-01-01 | 2018-01-10 | 9 days | 10 | 10 |
| (0, valid) | 2018-01-12 | 2018-01-13 | 1 days | 2 | 2 |
| (1, train) | 2018-01-06 | 2018-01-15 | 9 days | 10 | 10 |
| (1, valid) | 2018-01-17 | 2018-01-18 | 1 days | 2 | 2 |
| (2, train) | 2018-01-10 | 2018-01-19 | 9 days | 10 | 10 |
| (2, valid) | 2018-01-21 | 2018-01-22 | 1 days | 2 | 2 |
| (3, train) | 2018-01-15 | 2018-01-24 | 9 days | 10 | 10 |
| (3, valid) | 2018-01-26 | 2018-01-27 | 1 days | 2 | 2 |