[1]:
import matplotlib.pylab as plt
import numpy as np
from collections import Counter
Datasets
Scikit-lego includes several datasets which can be used for testing purposes. Each dataset has different options for returning the data:
When setting
as_frameto True, the data, including the target, is returned as a dataframe.When setting
return_X_yto True, the data is returned directly as(data, target)instead of a dict object.
This notebook describes the different sets included in Scikit-lego:
sklego.datasets.load_abaloneloads in the abalone datasetsklego.datasets.load_arrestsloads in a dataset with fairness concernssklego.datasets.load_chickenloads in the joyful chickweight datasetsklego.datasets.load_heroesloads a heroes of the storm datasetsklego.datasets.load_heartsloads a dataset about heartssklego.datasets.load_penguinsloads a lovely dataset about penguinssklego.datasets.fetch_creditcardfetch a fraud dataset from openmlsklego.datasets.make_simpleseriesmake a simulated timeseries
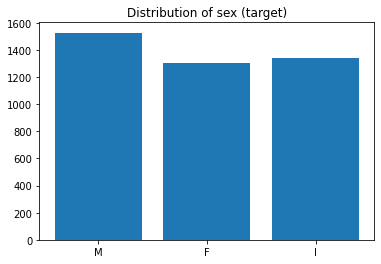
Abalone
Loads the abalone dataset where the goal is to predict the gender of the creature.
[2]:
from sklego.datasets import load_abalone
df_abalone = load_abalone(as_frame=True)
df_abalone.head()
[2]:
| sex | length | diameter | height | whole_weight | shucked_weight | viscera_weight | shell_weight | rings | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M | 0.455 | 0.365 | 0.095 | 0.5140 | 0.2245 | 0.1010 | 0.150 | 15 |
| 1 | M | 0.350 | 0.265 | 0.090 | 0.2255 | 0.0995 | 0.0485 | 0.070 | 7 |
| 2 | F | 0.530 | 0.420 | 0.135 | 0.6770 | 0.2565 | 0.1415 | 0.210 | 9 |
| 3 | M | 0.440 | 0.365 | 0.125 | 0.5160 | 0.2155 | 0.1140 | 0.155 | 10 |
| 4 | I | 0.330 | 0.255 | 0.080 | 0.2050 | 0.0895 | 0.0395 | 0.055 | 7 |
[3]:
X, y = load_abalone(return_X_y=True)
plt.bar(Counter(y).keys(), Counter(y).values())
plt.title('Distribution of sex (target)');
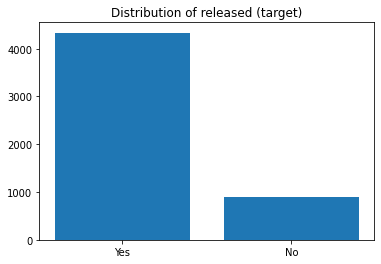
Arrests
Loads the arrests dataset which can serve as a benchmark for fairness. It is data on the police treatment of individuals arrested in Toronto for simple possession of small quantities of marijuana. The goal is to predict whether or not the arrestee was released with a summons while maintaining a degree of fairness.
[4]:
from sklego.datasets import load_arrests
df_arrests = load_arrests(as_frame=True)
df_arrests.head()
[4]:
| released | colour | year | age | sex | employed | citizen | checks | |
|---|---|---|---|---|---|---|---|---|
| 0 | Yes | White | 2002 | 21 | Male | Yes | Yes | 3 |
| 1 | No | Black | 1999 | 17 | Male | Yes | Yes | 3 |
| 2 | Yes | White | 2000 | 24 | Male | Yes | Yes | 3 |
| 3 | No | Black | 2000 | 46 | Male | Yes | Yes | 1 |
| 4 | Yes | Black | 1999 | 27 | Female | Yes | Yes | 1 |
[5]:
X, y = load_arrests(return_X_y=True)
plt.bar(Counter(y).keys(), Counter(y).values())
plt.title('Distribution of released (target)');
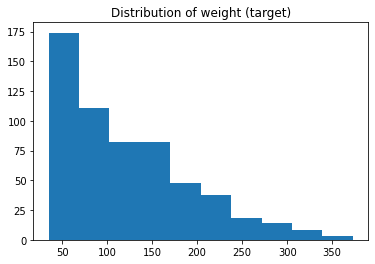
Chicken
Loads the chicken dataset. The chicken data has 578 rows and 4 columns from an experiment on the effect of diet on early growth of chicks. The body weights of the chicks were measured at birth and every second day thereafter until day 20. They were also measured on day 21. There were four groups on chicks on different protein diets.
[6]:
from sklego.datasets import load_chicken
df_chicken = load_chicken(as_frame=True)
df_chicken.head()
[6]:
| weight | time | chick | diet | |
|---|---|---|---|---|
| 0 | 42 | 0 | 1 | 1 |
| 1 | 51 | 2 | 1 | 1 |
| 2 | 59 | 4 | 1 | 1 |
| 3 | 64 | 6 | 1 | 1 |
| 4 | 76 | 8 | 1 | 1 |
[7]:
X, y = load_chicken(return_X_y=True)
plt.hist(y)
plt.title('Distribution of weight (target)');
Heroes
A dataset from a video game: “heroes of the storm”. The goal of the dataset is to predict the attack type. Note that the pandas dataset returns more information.
[8]:
from sklego.datasets import load_heroes
df_heroes = load_heroes(as_frame=True)
df_heroes.head()
[8]:
| name | attack_type | role | health | attack | attack_spd | |
|---|---|---|---|---|---|---|
| 0 | Artanis | Melee | Bruiser | 2470.0 | 111.0 | 1.00 |
| 1 | Chen | Melee | Bruiser | 2473.0 | 90.0 | 1.11 |
| 2 | Dehaka | Melee | Bruiser | 2434.0 | 100.0 | 1.11 |
| 3 | Imperius | Melee | Bruiser | 2450.0 | 122.0 | 0.83 |
| 4 | Leoric | Melee | Bruiser | 2550.0 | 109.0 | 0.77 |
[9]:
X, y = load_heroes(return_X_y=True)
plt.bar(Counter(y).keys(), Counter(y).values())
plt.title('Distribution of attack_type (target)');

Hearts
Loads the Cleveland Heart Diseases dataset. The goal is to predict the presence of a heart disease (target values 1, 2, 3, and 4). The data originates from research to heart diseases by four institutions and originally contains 76 attributes. Yet, all published experiments refer to using a subset of 13 features and one target. This implementation loads the Cleveland dataset of the research which is the only set used by ML researchers to this date.
[10]:
from sklego.datasets import load_hearts
df_hearts = load_hearts(as_frame=True)
df_hearts.head()
[10]:
| age | sex | cp | trestbps | chol | fbs | restecg | thalach | exang | oldpeak | slope | ca | thal | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 1 | 145 | 233 | 1 | 2 | 150 | 0 | 2.3 | 3 | 0 | fixed | 0 |
| 1 | 67 | 1 | 4 | 160 | 286 | 0 | 2 | 108 | 1 | 1.5 | 2 | 3 | normal | 1 |
| 2 | 67 | 1 | 4 | 120 | 229 | 0 | 2 | 129 | 1 | 2.6 | 2 | 2 | reversible | 0 |
| 3 | 37 | 1 | 3 | 130 | 250 | 0 | 0 | 187 | 0 | 3.5 | 3 | 0 | normal | 0 |
| 4 | 41 | 0 | 2 | 130 | 204 | 0 | 2 | 172 | 0 | 1.4 | 1 | 0 | normal | 0 |
[11]:
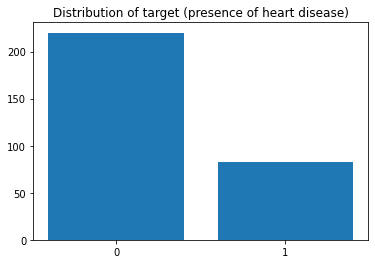
X, y = load_hearts(return_X_y=True)
y_counted = Counter([str(integer) for integer in y])
plt.bar(y_counted.keys(), y_counted.values())
plt.title('Distribution of target (presence of heart disease)');
Load penguins
Loads the penguins dataset, which is a lovely alternative for the iris dataset. We’ve added this dataset for educational use.
Data were collected and made available by Dr. Kristen Gorman and the Palmer Station, Antarctica LTER, a member of the Long Term Ecological Research Network. The goal of the dataset is to predict which species of penguin a penguin belongs to.
[12]:
from sklego.datasets import load_penguins
df_penguins = load_penguins(as_frame=True)
df_penguins.head()
[12]:
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | |
|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | male |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | female |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | female |
| 3 | Adelie | Torgersen | NaN | NaN | NaN | NaN | NaN |
| 4 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | female |
[13]:
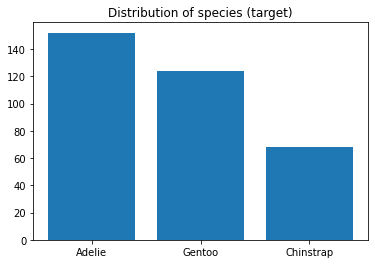
X, y = load_penguins(return_X_y=True)
plt.bar(Counter(y).keys(), Counter(y).values())
plt.title('Distribution of species (target)');
Fetch creditcard
Load the creditcard dataset. Download it if necessary.
Note that internally this is using fetch_openml from scikit-learn, which is experimental.
============== ==============
Samples total 284807
Dimensionality 29
Features real
Target int 0, 1
============== ==============
The datasets contains transactions made by credit cards in September 2013 by european cardholders. This dataset present transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
Please cite: Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015
[14]:
from sklego.datasets import fetch_creditcard
dict_creditcard = fetch_creditcard(as_frame=True)
df_creditcard = dict_creditcard['frame']
df_creditcard.head()
[14]:
| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 rows × 30 columns
[15]:
X, y = dict_creditcard['data'], dict_creditcard['target']
plt.bar(Counter(y).keys(), Counter(y).values())
plt.title('Distribution of fraud (target)');

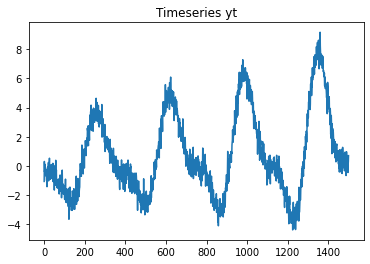
Simple time series
Generate a very simple timeseries dataset to play with. The generator assumes to generate daily data with a season, trend and noise.
[16]:
from sklego.datasets import make_simpleseries
df_simpleseries = make_simpleseries(as_frame=True, n_samples=1500, trend=0.001)
df_simpleseries.head()
[16]:
| yt | |
|---|---|
| 0 | -1.066620 |
| 1 | 0.303379 |
| 2 | -0.412812 |
| 3 | -0.227176 |
| 4 | 0.105581 |
[17]:
plt.plot(df_simpleseries['yt'])
plt.title('Timeseries yt');